返回目录:旅游景点
机器学习概述
机器学习是利用计算机揭示数据背后的真正含义。它旨在将无序数据转换成有用的信息。它是一门多学科交叉的学科,涉及概率论、统计学、近似理论、凸分析、算法复杂性理论等学科。专攻计算机如何模拟或实现人类学习行为的研究,为了获得新的知识或技能,重组现有的知识结构以不断提高自身的性能。它是人工智能的核心,也是计算机智能化的根本途径。它的应用涵盖了人工智能的所有领域。它主要使用归纳、综合而不是演绎。
海量的数据获取有用的信息机器学习研究的意义
机器学习是一门人工智能科学。该领域的主要研究对象是人工智能,尤其是如何提高特定算法在经验学习中的性能。机器学习是对可以通过经验自动改进的计算机算法的研究。”“机器学习使用数据或过去的经验来优化计算机程序的性能标准。英语中一个经常被引用的定义是:一个计算机程序,如果它在测试任务中的表现,用P来衡量,随着经验e而提高
机器学习已被广泛应用,如数据挖掘、计算机视觉、自然语言处理、生物识别、搜索引擎、医疗诊断、信用卡欺诈检测、证券市场分析、脱氧核糖核酸测序、语音和手写识别、战略游戏和机器人应用。
机器学习场景
例如:识别动物猫模式识别(官方标准):人们通过大量的经验,得到结论,从而判断它就是猫。机器学习(数据学习):人们通过阅读进行学习,观察它会叫、小眼睛、两只耳朵、四条腿、一条尾巴,得到结论,从而判断它就是猫。深度学习(深入数据):人们通过深入了解它,发现它会'喵喵'的叫、与同类的猫科动物很类似,得到结论,从而判断它就是猫。(深度学习常用领域:语音识别、图像识别)模式识别(pattern recognition): 模式识别是最古老的(作为一个术语而言,可以说是很过时的)。我们把环境与客体统称为“模式”,识别是对模式的一种认知,是如何让一个计算机程序去做一些看起来很“智能”的事情。通过融于智慧和直觉后,通过构建程序,识别一些事物,而不是人,例如: 识别数字。机器学习(machine learning): 机器学习是最基础的(当下初创公司和研究实验室的热点领域之一)。在90年代初,人们开始意识到一种可以更有效地构建模式识别算法的方法,那就是用数据(可以通过廉价劳动力采集获得)去替换专家(具有很多图像方面知识的人)。“机器学习”强调的是,在给计算机程序(或者机器)输入一些数据后,它必须做一些事情,那就是学习这些数据,而这个学习的步骤是明确的。机器学习(Machine Learning)是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身性能的学科。深度学习(deep learning): 深度学习是非常崭新和有影响力的前沿领域,我们甚至不会去思考-后深度学习时代。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。参考地址:深度学习 vs 机器学习 vs 模式识别深度学习 百科资料机器学习已经应用于许多领域,远远超出了大多数人的想象,涵盖了计算机科学、工程技术和统计学等许多学科。
搜索引擎: 根据你的搜索点击,优化你下次的搜索结果,是机器学习来帮助搜索引擎判断哪个结果更适合你(也判断哪个广告更适合你)。垃圾邮件: 会自动的过滤垃圾广告邮件到垃圾箱内。超市优惠券: 你会发现,你在购买小孩子尿布的时候,售货员会赠送你一张优惠券可以兑换6罐啤酒。邮局邮寄: 手写软件自动识别寄送贺卡的地址。申请贷款: 通过你最近的金融活动信息进行综合评定,决定你是否合格。机器学习的组成
主任务
分类(classification):将实例数据划分到合适的类别中。应用实例:判断网站是否被黑客入侵(二分类 ),手写数字的自动识别(多分类)回归(regression):主要用于预测数值型数据。应用实例:股票价格波动的预测,房屋价格的预测等。监督学习
必须确定目标变量的值,以便机器学习算法可以发现特征和目标变量之间的关系。在监督学习中,给定一组数据,我们知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系。 (包括:分类和回归)样本集:训练数据 + 测试数据训练样本 = 特征(feature) + 目标变量(label: 分类-离散值/回归-连续值)特征通常是训练样本集的列,它们是独立测量得到的。目标变量: 目标变量是机器学习预测算法的测试结果。在分类算法中目标变量的类型通常是标称型(如:真与假),而在回归算法中通常是连续型(如:1~100)。监督学习需要注意的问题:偏置方差权衡功能的复杂性和数量的训练数据输入空间的维数噪声中的输出值知识表示:可以采用规则集的形式【例如:数学成绩大于90分为优秀】可以采用概率分布的形式【例如:通过统计分布发现,90%的同学数学成绩,在70分以下,那么大于70分定为优秀】可以使用训练样本集中的一个实例【例如:通过样本集合,我们训练出一个模型实例,得出 年轻,数学成绩中高等,谈吐优雅,我们认为是优秀】无人监督学习
在机器学习,无监督学习的问题是,在未加标签的数据中,试图找到隐藏的结构。因为提供给学习者的实例是未标记的,因此没有错误或报酬信号来评估潜在的解决方案。无监督学习是密切相关的统计数据密度估计的问题。然而无监督学习还包括寻求,总结和解释数据的主要特点等诸多技术。在无监督学习使用的许多方法是基于用于处理数据的数据挖掘方法。数据没有类别信息,也不会给定目标值。非监督学习包括的类型:聚类:在无监督学习中,将数据集分成由类似的对象组成多个类的过程称为聚类。密度估计:通过样本分布的紧密程度,来估计与分组的相似性。此外,无监督学习还可以减少数据特征的维度,以便我们可以使用二维或三维图形更加直观地展示数据信息。强化学习
该算法可以训练程序做出一定的决策。该程序在特定情况下尝试所有可能的行动,记录不同行动的结果,并试图找到最佳的行动来做出决定。马尔可夫决策过程属于这种算法。
培训过程
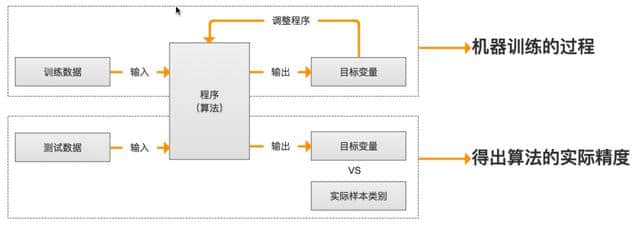
算法摘要
机器学习的使用
算法选择中需要考虑的两个问题
算法场景预测明天是否下雨,因为可以用历史的天气情况做预测,所以选择监督学习算法给一群陌生的人进行分组,但是我们并没有这些人的类别信息,所以选择无监督学习算法、通过他们身高、体重等特征进行处理。需要收集或分析的数据是什么例如

机器学习开发过程
收集数据: 收集样本数据准备数据: 注意数据的格式分析数据: 为了确保数据集中没有垃圾数据;如果是算法可以处理的数据格式或可信任的数据源,则可以跳过该步骤;另外该步骤需要人工干预,会降低自动化系统的价值。训练算法: [机器学习算法核心]如果使用无监督学习算法,由于不存在目标变量值,则可以跳过该步骤测试算法: [机器学习算法核心]评估算法效果使用算法: 将机器学习算法转为应用程序机器学习的数学基础
微积分统计学/概率论线性代数机器学习工具
Python语言
可执行伪代码Python比较流行:使用广泛、代码范例多、丰富模块库,开发周期短Python语言的特色:清晰简练、易于理解Python语言的缺点:唯一不足的是性能问题Python相关的库科学函数库:SciPy、NumPy(底层语言:C和Fortran)绘图工具库:Matplotlib数据分析库 Pandas数学工具
Matlab附件:机器学习术语
模型(model):计算机层面的认知学习算法(learning algorithm),从数据中产生模型的方法数据集(data set):一组记录的合集示例(instance):对于某个对象的描述样本(sample):也叫示例属性(attribute):对象的某方面表现或特征特征(feature):同属性属性值(attribute value):属性上的取值属性空间(attribute space):属性张成的空间样本空间/输入空间(samplespace):同属性空间特征向量(feature vector):在属性空间里每个点对应一个坐标向量,把一个示例称作特征向量维数(dimensionality):描述样本参数的个数(也就是空间是几维的)学习(learning)/训练(training):从数据中学得模型训练数据(training data):训练过程中用到的数据训练样本(training sample):训练用到的每个样本训练集(training set):训练样本组成的集合假设(hypothesis):学习模型对应了关于数据的某种潜在规则真相(ground-truth):真正存在的潜在规律学习器(learner):模型的另一种叫法,把学习算法在给定数据和参数空间的实例化预测(prediction):判断一个东西的属性标记(label):关于示例的结果信息,比如我是一个“好人”。样例(example):拥有标记的示例标记空间/输出空间(label space):所有标记的集合分类(classification):预测是离散值,比如把人分为好人和坏人之类的学习任务回归(regression):预测值是连续值,比如你的好人程度达到了0.9,0.6之类的二分类(binary classification):只涉及两个类别的分类任务正类(positive class):二分类里的一个反类(negative class):二分类里的另外一个多分类(multi-class classification):涉及多个类别的分类测试(testing):学习到模型之后对样本进行预测的过程测试样本(testing sample):被预测的样本聚类(clustering):把训练集中的对象分为若干组簇(cluster):每一个组叫簇监督学习(supervised learning):典范--分类和回归无监督学习(unsupervised learning):典范--聚类未见示例(unseen instance):“新样本“,没训练过的样本泛化(generalization)能力:学得的模型适用于新样本的能力分布(distribution):样本空间的全体样本服从的一种规律独立同分布(independent and identically distributed,简称i,i,d.):获得的每个样本都是独立地从这个分布上采样获得的。机器学习的基本补充
数据集的划分
训练集(Training set) —— 学习样本数据集,通过匹配一些参数来建立一个模型,主要用来训练模型。类比考研前做的解题大全。验证集(validation set) —— 对学习出来的模型,调整模型的参数,如在神经网络中选择隐藏单元数。验证集还用来确定网络结构或者控制模型复杂程度的参数。类比 考研之前做的模拟考试。测试集(Test set) —— 测试训练好的模型的分辨能力。类比 考研。这次真的是一考定终身。模型拟合度
欠拟合(Underfitting):模型没有很好地捕捉到数据特征,不能够很好地拟合数据,对训练样本的一般性质尚未学好。类比,光看书不做题觉得自己什么都会了,上了考场才知道自己啥都不会。过拟合(Overfitting):模型把训练样本学习“太好了”,可能把一些训练样本自身的特性当做了所有潜在样本都有的一般性质,导致泛化能力下降。类比,做课后题全都做对了,超纲题也都认为是考试必考题目,上了考场还是啥都不会。通俗地说,一句话既可以用不合适也可以用过度合适。不合时宜的是:“你太天真了!”过分合适的是:“你想得太多了!”。
通用模型指示器
正确率 —— 提取出的正确信息条数 / 提取出的信息条数召回率 —— 提取出的正确信息条数 / 样本中的信息条数F 值 —— 正确率 * 召回率 * 2 / (正确率 + 召回率)(F值即为正确率和召回率的调和平均值)例如:
例如,池塘里有1400条鲤鱼、300只虾和300只海龟。现在的目标是捕捉鲤鱼。他撒网,抓了700条鲤鱼、200只虾和100只乌龟。那么这些指标如下:准确率= 700/(700+200+100) = 70%召回率= 700/1400 = 50%离职率= 70% * 50% * 2/(70%+50%) = 58.3%
模型
分类问题 —— 说白了就是将一些未知类别的数据分到现在已知的类别中去。比如,根据你的一些信息,判断你是高富帅,还是穷屌丝。评判分类效果好坏的三个指标就是上面介绍的三个指标:正确率,召回率,F值。回归问题 —— 对数值型连续随机变量进行预测和建模的监督学习算法。回归往往会通过计算 误差(Error)来确定模型的精确性。聚类问题 —— 聚类是一种无监督学习任务,该算法基于数据的内部结构寻找观察样本的自然族群(即集群)。聚类问题的标准一般基于距离:簇内距离(Intra-cluster Distance) 和 簇间距离(Inter-cluster Distance) 。簇内距离是越小越好,也就是簇内的元素越相似越好;而簇间距离越大越好,也就是说簇间(不同簇)元素越不相同越好。一般的,衡量聚类问题会给出一个结合簇内距离和簇间距离的公式。可以直观地显示下图:

特征工程的一些小事情
特征选择 —— 也叫特征子集选择(FSS,Feature Subset Selection)。是指从已有的 M 个特征(Feature)中选择 N 个特征使得系统的特定指标最优化,是从原始特征中选择出一些最有效特征以降低数据集维度的过程,是提高算法性能的一个重要手段,也是模式识别中关键的数据预处理步骤。特征提取 —— 特征提取是计算机视觉和图像处理中的一个概念。它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征提取的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点,连续的曲线或者连续的区域。以下是功能项目的示意图:

其他的
Learning rate —— 学习率,通俗地理解,可以理解为步长,步子大了,很容易错过最佳结果。就是本来目标尽在咫尺,可是因为我迈的步子很大,却一下子走过了。步子小了呢,就是同样的距离,我却要走很多很多步,这样导致训练的耗时费力还不讨好。一个总结的知识点很棒的链接 :https://zhuanlan.zhihu.com/p/25197792